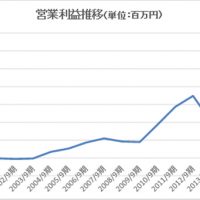
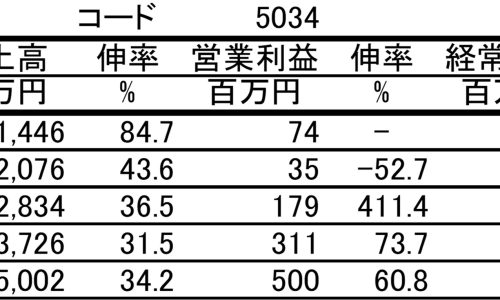
図は100円ショップの大手3社であるセリア、ダイソー、キャンドゥの営業利益推移を比較したものである。2010年辺りまでは各社団子状態であったが、ここ5年ほどでセリアがダントツの存在になりつつあることがわかる。(なお、売上高でダントツのダイソーを運営する大創産業は未上場のため、データが不明であり分析対象には入っていない。)
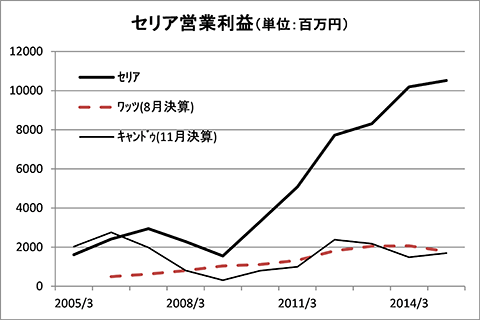
この数年で同社だけが大きく利益を伸ばしている背景には、データ解析による自動発注システムの導入がある。同社では店員が商品を発注するための発注支援システムを独自開発したことで2005/3期に3.2%であった営業利益率が、2007/3期には5.0%と大きく上昇した。しかし、その時点までにはヒトによる発注の限界を感じ始めていた。
そこで、2006年には「自律型仮説検証モデル」と呼ぶ新たな発注支援システムの実験を開始している。このシステムは自動発注システムであり、まずは25%の自動発注から始め、徐々に自動化率を上げてゆくことで、60%まで実験的に持って行った。その間、実は営業利益率は2008/3期3.6%、2009/3期には2.3%と大きく低下している。
しかし、これは仮説検証を行っていたためで、実際はこの検証結果をもとに、自動発注比率を95%まで持って行った。その結果、営業利益率は2010/3期4.3%→2011/3期6.1%→2012/3期8.2%と急速に上昇している。このようにして同社は同業他社を利益水準で大きく上回る状況を実現している。まさに、データ解析の威力というを認識させる現象であろう。
実際のシステムの詳細はもちろん企業秘密であり、公にはされていない。しかし、会社側から開示されている資料からいくつかのヒントを得ることはできる。
そもそもシステムを用いて店員が発注する場合、どうしてもデータを追いかけ、需要の深追いをしてしまうことになる。つまり、売れているものをたくさん置くようになるということである。これはアンカリング効果と呼ばれるものである。アンカリング効果とは、提示された特定の数値や情報が印象に残って基準点(アンカー) となり、判断に影響を及ぼす心理傾向のことを言う。しかし、こうなると間違いなく需要の変化には追いつけないのである。そこで、セリアではシステムによる完全自動発注に切り替えることに挑戦したのである。
仮にデータ分析をして、販売データが低い商品があったとすると、それをそのまま単純に陳列から排除してしまうと、在庫が増加してしまう。しかし、人はそのように行動してしまいがちである。よりロジカルに考えれば、むしろ陳列を増やして売り切るまで辛抱することも必要だという考え方である。システムであれば、それも実現可能である。
また、出てきたデータの確からしさも常に検証する必要がある。どうしても顕在化した数字で、成功、失敗を判断しがちであるが、この場合データの中身の確認をする必要がある。ここがわからないと、データ分析を使う意味がないということである。つまり、売れていないものは、並べていないから売れていないということも十分にあるわけで、常にそういった検証が必要になる。
有賀の眼
昨今、コンピュータ性能の向上で、ビッグデータの解析がかつてに比較して大幅に容易になったという言葉を耳にする。しかし、たくさんのデータを既成のシステムで分析させれば答えが出る、という簡単な世界ではない。分析結果をどう解釈するかが重要であるが、そのためにはやはり分析結果の意味を十分に考える必要があるということだ。
しばしば言われることであるが、何事も専門家丸投げではうまく行かないものである。特にコンピュータやデータの世界は、専門家に任せておくと大いなる無駄が発生しやすい世界である。そのリスクをなくすためには、経営者はデータに強くなる必要がある。それが難しければ、少なくとも経営に近いところに、データの扱い方に精通した人をおく必要があるだろう。